From tabular research data to reusable Linked Data. The KIDA Linked Data Services connect two complementary components: the RDF4RiskAssessment Toolkit transforms CSV and Excel files into semantically enriched RDF, while the KIDA Research Data Hub provides an environment for discovering, exploring and reusing RDF-based research data.
Open one of the services directly through the cards below, or read more about how the Toolkit and the Data Hub work together to support FAIR data publication, semantic interoperability and data reuse in risk assessment and life sciences.
RDF4RiskAssessment Toolkit
Prepare research data as RDF
Convert tabular research data into semantically enriched, interoperable RDF through a guided workflow.
KIDA Research Data Hub
Discover and reuse Linked Data
Explore RDF-based research data, shared concepts and semantic services in a reusable data platform.
RDF4RiskAssessment Toolkit
The RDF4RiskAssessment Toolkit is a web-based software framework for converting tabular research data into FAIR, machine-readable RDF. It supports researchers and risk assessors in transforming CSV and Excel files into structured Linked Data without requiring prior Semantic Web expertise.
The toolkit was developed within the national research project KI- & Daten-Akzelerator (KIDA). It addresses a recurring problem in risk assessment and life sciences: valuable research data is often stored in heterogeneous tables using local column names, inconsistent terminology and project-specific formats. This limits reuse, cross-study comparison and machine-supported analysis.
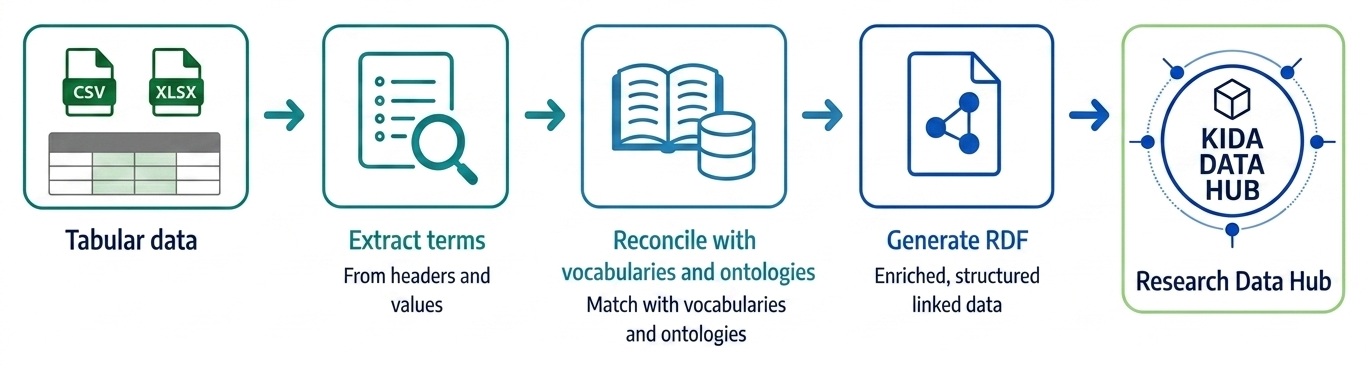
RDF4RiskAssessment provides a guided workflow that helps users extract terms from tabular datasets, reconcile them with established vocabularies and ontologies, and generate semantically enriched RDF. The resulting RDF can subsequently be integrated into semantic data platforms such as the KIDA Research Data Hub.
Purpose
The toolkit is designed to make research data interoperable at an early stage of data preparation. Instead of treating tables as isolated files, RDF4RiskAssessment helps represent the meaning of variables, values, metadata and references using shared identifiers and standard RDF structures.
- Convert tabular research data to RDF from common formats such as CSV and XLSX.
- Generate semantic mappings between local dataset terms and external ontology or vocabulary concepts.
- Support FAIR data publication through metadata, provenance information and persistent identifiers.
- Enable cross-dataset linking through shared URIs and SKOS-based vocabulary alignment.
- Support validation by reconstructing human-readable tabular representations from generated RDF.
Workflow
The software follows a modular workflow. Each step can be used individually or as part of an end-to-end process for preparing tabular research data as FAIR Linked Data.
1. Generate a matching table
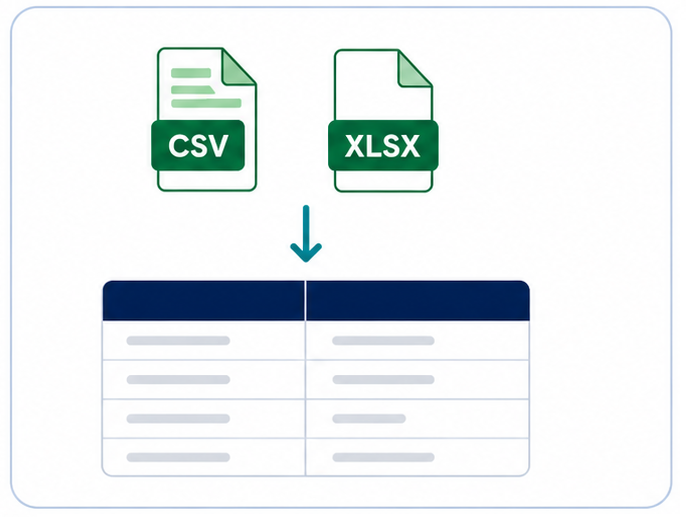
The user uploads a CSV or Excel file. The toolkit extracts relevant terms from column headers and selected cell values and creates a structured matching table that serves as the basis for semantic enrichment.
2. Reconcile terms
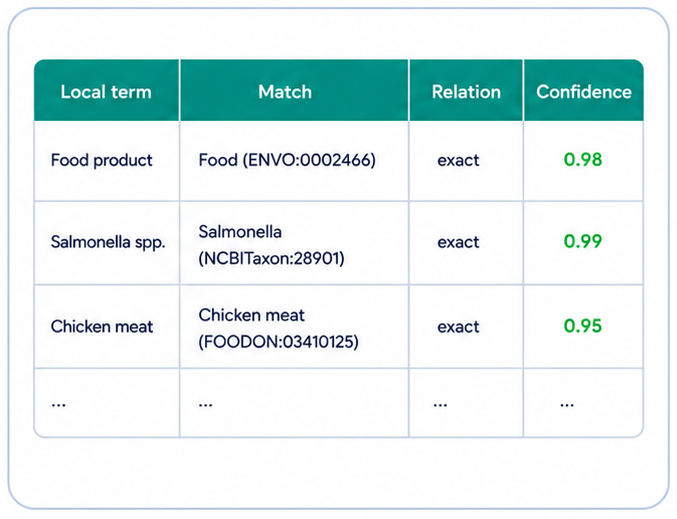
Terms are matched against external terminology services and knowledge sources. Candidate mappings can be reviewed, corrected and documented with mapping relations such as exact, close or broad matches.
3. Generate RDF
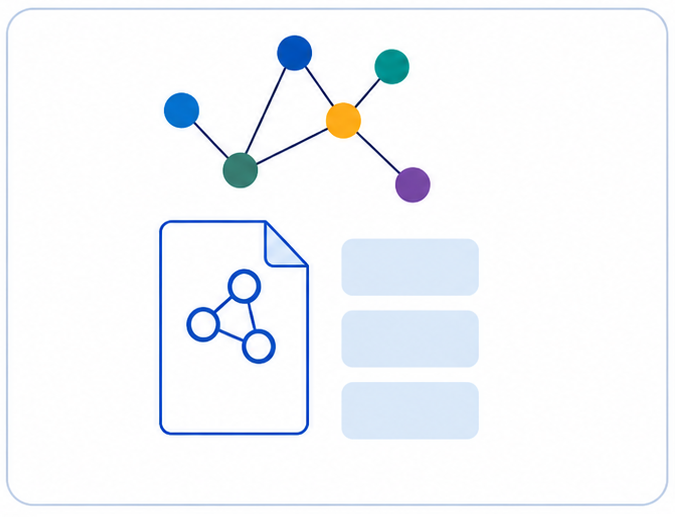
The curated mappings are used to generate RDF graphs. The output can include dataset metadata, literature references, SKOS vocabularies and the converted research data itself. RDF serialisations such as Turtle, TriG or JSON-LD can be generated depending on the target system.
4. Convert RDF back to tables
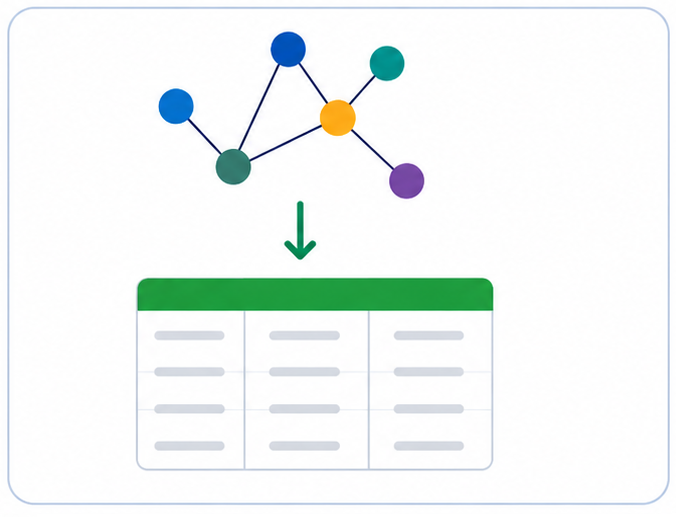
A reverse RDF-to-table service can reconstruct a spreadsheet-like representation from the RDF output. This enables users to inspect and validate the generated graph in a familiar format.
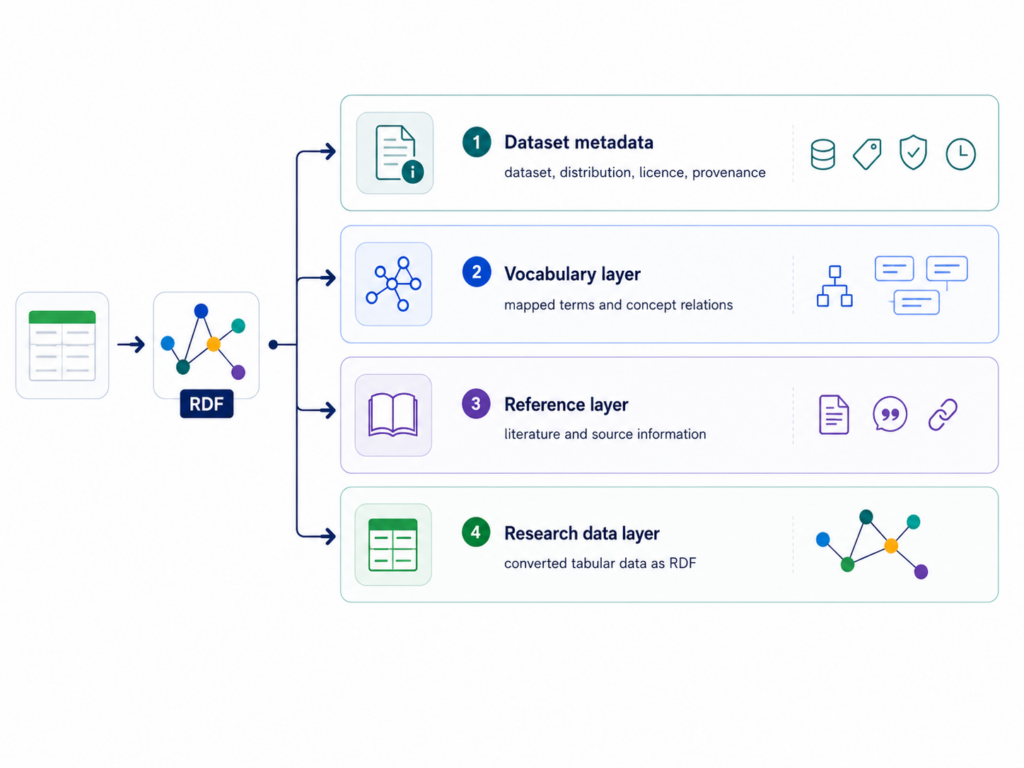
Data model
The generated RDF follows a layered structure that separates original research data from metadata, vocabulary mappings and bibliographic information. This keeps the output transparent and easier to reuse in data catalogues, SPARQL endpoints and downstream analytical workflows.
Semantic enrichment
The reconciliation step is central to making local dataset terms interoperable. It allows users to connect project-specific labels, such as column names, measurement terms, organisms, food matrices or analytical parameters, to established identifiers from external vocabularies and databases.
- SSSOM-compatible matching tables provide a structured and reviewable exchange format for mappings.
- SKOS mapping relations document whether a mapping is exact, close, broad or otherwise related.
- Confidence scores and provenance distinguish automatically generated suggestions from manually curated mappings.
- Optional LLM-assisted reconciliation supports the evaluation of ambiguous terms by querying multiple providers and documenting the decision steps.
Application context
The toolkit has been applied to research data from diverse domains relevant to risk assessment and the life sciences. To date, 14 datasets from 6 publications have been converted into Linked Data, resulting in approximately 1,860 mapped vocabulary concepts.
- Preparing tabular research data for publication as FAIR Linked Data.
- Harmonising terminology across studies and projects.
- Linking datasets through shared biological, chemical, food safety or epidemiological concepts.
- Building RDF datasets for SPARQL-based search and analysis.
- Generating machine-readable inputs for knowledge graphs and AI-supported data workflows.

KIDA Research Data Hub
The KIDA Research Data Hub is a semantic data platform for hosting, discovering and reusing Linked Data from research projects in risk assessment and related life science domains. RDF generated with the RDF4RiskAssessment Toolkit can be integrated into the hub and made accessible through semantic search and query services.
While the toolkit focuses on preparing and semantically enriching tabular datasets, the Data Hub provides the environment for working with the resulting RDF: exploring datasets, querying linked information, reusing vocabularies and retaining provenance across the data lifecycle.
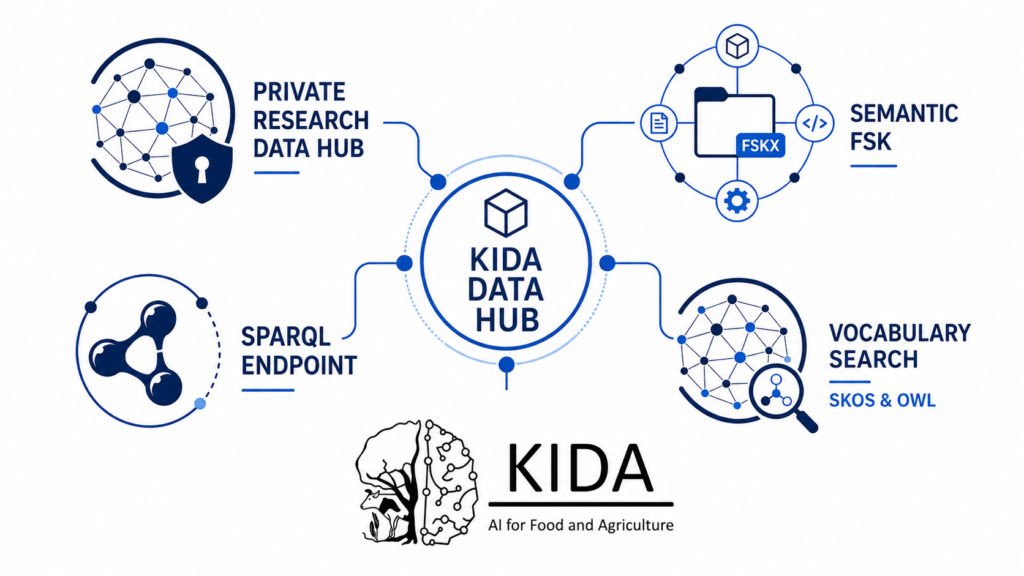
Core services
Research data discovery
Browse and identify RDF-based datasets from research contexts relevant to One Health, food safety and risk assessment.
Semantic query access
Access information through shared semantic concepts and structured RDF queries rather than relying only on individual table structures.
Vocabulary exploration
Inspect and reuse terminology resources that connect datasets through consistent concepts, identifiers and mappings.
Provenance and reuse
Preserve links between datasets, source publications, semantic transformations and generated outputs to support transparent reuse.
Connection to the RDF4RiskAssessment Toolkit
The two services form a connected workflow. The RDF4RiskAssessment Toolkit prepares tabular research data by extracting terms, establishing semantic mappings and generating RDF. The KIDA Research Data Hub then provides an environment in which this RDF can be integrated, explored and reused across datasets and projects.
- Input: heterogeneous research tables in CSV and Excel format.
- Transformation: term extraction, semantic reconciliation and RDF generation using the RDF4RiskAssessment Toolkit.
- Reuse: integration of semantically enriched RDF into the KIDA Research Data Hub for discovery and analysis.
Access and related information
- RDF4RiskAssessment Toolkit source code: GitHub repository
- KIDA Research Data Hub: Open platform
- Related FoodRisk-Labs service: OH Data
- Conference contribution: SWAT4HCLS 2026 accepted submissions